Perspectives of the further development of the Correspondence Metadata Interchange Format (CMIF)
Historical correspondences are generally only partially edited—focusing often on one person or only on the correspondence between two persons. Thus edited letters[1] remain isolated in the context of a certain scholarly edition. Searches across scholarly projects and editions are time-consuming and difficult.
To solve this problem[2], the Correspondence Metadata Interchange Format (CMIF), based on the TEI Guidelines, was developed. With the help of the CMIF scholarly editions should be enabled to provide the metadata of their edited letters in a machine-readable way – online and under a free license. These files can be retrieved and processed by digital scholarly editions, databases or web services (like correspSearch).
This article presents the current state of the CMIF and outlines the possibilities of the further development. Interested scholars are invited to give feedback in the comment section below or on the mailing list of the TEI Correspondence SIG.
Background
The initiative for the Correspondence Metadata Interchange Format (and for the web service correspSearch, which builds up on it) arose in a workshop on “Interfaces for scholarly editions of letters around 1800”, which took place in Berlin in February 2014 and was organized by Anne Baillot (HU Berlin) and Markus Schnöpf (BBAW).
An important precondition for the development of the CMIF was an initiative that had been started shortly before that workshop by members of the TEI Correspondence Special Interest Group (SIG), namely Marcel Illetschko, Sabine Seifert and Peter Stadler. They made a proposal for a TEI element correspDesccorrespDesccorrespDesc
The CMIF was developed after the above-mentioned workshop on the basis of the first drafts of correspDesc. The format mainly consists of multiple correspDesc elements, each of which represent an edited letter. In addititon, metadata on the CMIF file itself is stored in the document, thus completing it as a TEI-XML file.
Since then the CMIF has been developed and maintained by the TEI Correspondence SIG. The CMIF-ODD and examples are provided online in a GitHub repository of the Special Interest Group. Already provided CMI files are aggregated by and made accessible through the web service correspSearch, which was developed for this purpose by TELOTA, the Digital Humanities initiative of the Berlin-Brandenburg Academy of Sciences and Humanities.
Purpose and preliminary considerations
The purpose of the Correspondence Metadata Interchange Format (and of the web service correspSearch) is to make letters in scholarly editions searchable, retrievable and connectable across editions, projects and institutions. This way scholars shall be supported in their search for edited letters.
The CMIF contains only metadata, only in a condensed form. It is not intended to be a substitute for a detailed TEI header, but to provide the most important metadata for the interchange between digital publications and tools. The idea behind the CMIF is (in broad terms) to provide the index of letters and the indexes of mentioned persons, publications etc. like it will be normally done in scholarly editions of letters – but in a machine-readable way and under a free license to enable automated interchange. For this purpose it is necessary to balance the CMIF tag selection between desirable features on the one hand and necessity to keep the format as simple as possible on the other hand.
Providing a CMIF file has no consequences for the technology and formats used by a scholarly edition itself. Therefore an edition, which will provide a CMI file, can otherwise be based on XML technologies, relational databases or be designed for print only.
The CMIF is intended for an automated interchange without any human intervention.[5] Thus the format is restrictive and clearly defined. The fact that the CMIF is derived from TEI XML has some advantages: the hierarchical structure of XML is well suited for metadata, because is it machine-readable and flexible in the sense that the provision of information can be optional (elements and attributes can be removed, if not applicable). The underlying TEI Guidelines are a de facto standard in the domain of digital scholarly edition and therefore well-known and commonly used by scholars. Furthermore elements and attributes from the TEI Guidelines meet the requirements of a CMIF very well as will be shown below.
Current state of CMIF
In the current CMI format the element correspDesc is used in a more restrictive and reduced manner than the TEI Guidelines originally allow for ordinary TEI Headers. The following figure gives you an overview:
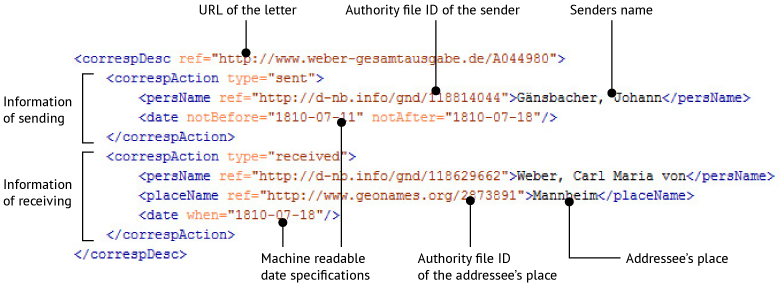
The chart shows schematically the different parts of a correspDesc element in the CMI format. The addressee will be noted in analogy to the sender. The example originates from an example provided by the TEI Correspondence SIG.
Each correspDesc element only contains the following information:
- Sender’s name and authority controlled ID
- Addressee’s name and authority controlled ID
- Date of writing and receiving
- Place of writing and receiving (name with authority controlled ID)
- Number of the letter in the scholarly edition
- URL of the edited letter
Each of these statements is optional. The encoding of names and places is flat, i.e. just the plain name is given. Detailed information should be retrieved from the scholarly edition itself or from an authority file.
It is important to add IDs from authority files (like VIAF, GND, GeoNames etc.) for persons and places to enable the interchange. Authority controlled IDs are the only possibility to identify persons and places across scholarly editions and projects.
In the TEI header of the CMI file are some mandatory data encoded, which are necessary for an index of letters in principle or for the processing of the CMI file. These include a CC-BY 4.0 license as well as the indication of the source the CMI file refers to within //sourceDesc//bibl.
Detailed information can be found in the documentation of the CMI format on the correspSearch website.
Perspectives on the further development
The CMI format currently covers only the basic information about letters. It should be extended in the future, because additional metadata could increase the search options significantly.
At this point we need to make a fundamental decision for the encoding, because in principle there are two ways of encoding correspondence metadata in a TEI based interchange format: On the one hand we could take the entire TEI header as the base and encode additional information there, just how it is be intended by the TEI Guidelines. On the other hand we could choose correspDesc as the main part of a metadata record and encode the information there. This latter option would mean to use correspDesc in a way it was not intended to originally: correspDesc would be containing information which are normally encoded in other places within the TEI header (like //sourceDesc//msDesc etc). Thus, the former option seems to be the better one at first glance. However,it results in a very complex TEI XML structure of multiple TEI headers in a teiCorpus whereas the CMIF should be as simple as possible to enable users to easily create, process and use CMI files. Furthermore, the approach, which based only on correspDesc, would emphasize that the CMIF isn’t meant to be a standard TEI header for correspondence material. So it seems to be recommendable to only use correspDesc for the further extensions of the CMIF.
At the moment the CMIF validates against TEI All. It is not certain, that this can be continued in the future. The interchange format should be semantically correct but also easy to understand and to process. In the prospective features outlined below it will be necessary to decide between TEI conformance and extension.
Below the possible additions to the CMI format are described, including an encoding proposal. This encoding proposal was developed with respect to the preliminary considerations mentioned above.
Archival Source
Information about the archival source for a letter description is useful for the CMI format for two reasons: Firstly, with this information multiple editions of one letter can be identified, grouped and linked. Secondly, archives, libraries as well as digital scholarly editions could automatically point to (even perhaps link to) edited letters in scholarly editions.
The problem is, that the identifiers for manuscripts commonly used in scholarly editions are not machine-readable, because they may differ slightly from project to project. Luckily, today many archives provide metadata records of their material online together with so called Uniform Resource Identifier (URI). These URI are only character sequences without white-spaces, often in the form of URLs. In Germany, for example, the “Kalliope Union Catalog” provides such URIs for each letter, which was recorded individually.
In the CMI format such URIs would preferably be encoded within correspDesc/@corresp. This would fit the (quite broad) definition in the TEI Guidelines. In CMIF ODD the content of this attribute could then be defined more strictly.
Textual basis
It would be useful to specify the type of the textual basis for a letter to enable researchers to evaluate the described correspondence already when looking at a search result based on CMI files in correspSearch.[6] The following list of types is based on the classification usually used in German scholarly editions:
- conjecture
- concept
- copy
- manuscript
Using these types would have some advantages: First, a user can immediately see whether the letter’s text exists or not, i.e. if the letter’s existence is just inferred from other letters, that mentioned it or if it actually exists as an archival source. Second, this way the data provided in a CMI file is more specific and clearly documented: in a correspondence description, which is marked as “conjecture” it is clear, that all information, which are part of it, are just an assumption.
Perhaps these information could be encoded in correspDesc/@evidence. The attribute @evidence isn’t allowed in correspDesc but should be used in the CMIF, because it seems well suited for this purpose regarding the definition in the TEI Guidelines.
Mentioned persons, places and publications
Without doubt it is useful to indicate the persons, places, publications etc. mentioned in a letter text. In a printed edition these information will be usually provided in the various indexes. In the CMIF this could be encoded in correspDesc/note:
<note type="mentioned"> <persName ref="http://viaf.org/viaf/24602065">Johann Wolfgang von Goethe</persName> <placeName ref="http://www.geonames.org/2874225">Mainz</placeName> <bibl ref="http://viaf.org/viaf/186077286">Die Leiden des jungen Werthers</bibl> <name ref="urn:lsid:ipni.org:names:164558-3:1.1">Kalanchoe pinnata</name> <event from="1793-04-14" to="1793-07-23">Belagerung von Mainz</event> </note>
Using event in note isn’t conform to the TEI guidelines, either, because the event element is only allowed in listEvent. If we want to use listEvent it would be consequent to use also listPerson, listBibl etc. Such a substructure would be possible, but would also make the encoding more complex – without any advantage in the processing or the semantic.
Even for the mentioned “entities”, the use of authority controlled IDs is necessary in an interchange format. Thus we should only consider to include those entities in the metadata record, for which authority files are available, i.e. persons, places and publications. Other entities such as objects and topics could also be provided in principle as long as authority files or standardized vocabularies exist, which we can refer to.
Nature of publication
The CMIF was developed especially with regard to scholarly editions, but in principle it should be suitable for the whole range of correspondence related publications and catalogues (digital or printed). For example, there are projects, which provide just transcriptions (and not a complete scholarly edition) of letters, but are nevertheless the best source available (besides the archival sources itself). Thus, with correspSearch being open for these data as well, it would be useful to indicate the nature of the data provided within a publication. I proposed the following properties, which can be combined:
- record
- abstract
- transcription
- comment
- facsimile
It seems obvious to store these information in the TEI header of the CMI file within //sourceDesc/bibl/@type, because they are usually valid for a whole publication. But of course, there are also projects, where these information differ from letter to letter, because (for example) facsimiles are available for a bunch of, but not all letters. In this case we have to consider a solution within correspDesc, perhaps in the @type attribute.
Up till now there are three possible values of //sourceDesc/bibl/@type within CMIF: “print”; “online” and “hybrid”. It seems that these types are not as useful as expected in the beginning, because sometimes it is not possible to clearly divide between these types: so on the one hand there are digital editions, which are not available online, on the other hand there are printed editions, which are digitized and available online. Furthermore, the information if an edited letter is available online or not is already expressed with correspDesc/@ref or, in case the whole publication is available, as a ref element in //sourceDesc//bibl.
Further improvements
Besides these major additions to the CMI format, it will be necessary to make some little improvements. For example, it should be possible to encode with the dates also the calendar, for which the date is valid. The TEI Guidelines already contain an attribute @calender for dates, which just has to be made available to CMIF via the CMIF ODD. Finally, it should also be considered, for which elements the attribute @cert should be allowed and how uncertainties could be further processed.
[1] In this article “letter” means also other pieces of correspondence like postcards or telegrams.
[2] The problem of dispersed correspondence is well-known and addressed by some articles (e.g. Stadler, Peter: Interoperabilität von digitalen Briefeditionen. In: Hanna Delf von Wolzogen, Rainer Falk (Hg.): Fontanes Briefe ediert (Fontaneana 12). Würzburg 2014, p. 278-287.) and projects (e.g. the Early Modern Letters Online, http://emlo.bodleian.ox.ac.uk/). This article will just focus on the more practical encoding issues in CMIF.
[3] The proposal was maintained and published on the GitHub repository of the TEI Correspondence SIG: https://github.com/TEI-Correspondence-SIG/correspDesc/blob/master/doc/proposal.html, a HTML view can retrieved here: https://htmlpreview.github.io/?https://raw.githubusercontent.com/TEI-Correspondence-SIG/correspDesc/master/doc/proposal.html
[4] Sabine Seifert, Marcel Illetschko, Peter Stadler: Towards a model for encoding correspondence in the TEI. Developing and implementing <correspDesc>. In: Journal of the Text Encoding Initiative [Online], Issue 9. (to be published)
[5] See also Bauman, Syd. “Interchange vs. Interoperability.” In: Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). doi:10.4242/BalisageVol7.Bauman01.
[6] Thanks to Dr. Gabriele Radecke from the Fontane-Arbeitsstelle at the Georg August University in Göttingen, which propose such a feature.
Kommentare
6 Kommentare zu “Perspectives of the further development of the Correspondence Metadata Interchange Format (CMIF)”
-
Herausgeber
-
 DHd-Blog
DHd-Blog
[…] a great dissemination campaign towards editors of letters corpora, inviting them to implement the Correspondence Metadata Interchange Format – and add their corpus to the correspSearch interface. And then maybe even play with the […]
Liebe Leute, schöner Beitrag voll sinnvoller Überlegungen! Eine Anregung: ich finde es in solchen Zusammenhängen immer sinnvoll, auch negative Ergebnisse explizit zu machen. Was ich meine wäre z.B. in eurem Beispiel http://digiversity.net/wp-content/uploads/2015/10/correspDesc_EN.png der fehlende Absendeort. So wird klar, dass der nicht in der Datenübertragung verloren gegangen ist, sondern in der Vorlage fehlt („o.O.“) oder in den ursprünglichen metadaten aus anderen Gründen nicht enthalten war. Analog dazu würde ich auch mit normdaten-verweisen umgehen, um klar zu machen, dass diese zum Zeitpunkt der Integration der Daten entweder nicht vom Datengeber recherchiert wurde oder dass sehr wohl recherchiert wurde, aber keine normdaten zu dieser Person oder diesem Ort vorhanden sind. Müsste also als Verweis als wert in @ref.Das jeweils in cmif einfach wegzulassen, finde ich unzureichend. Z.B. „o.D.“ und „o.O.“ „no_authority“ o.Ä. sind wichtige Informationen. Mehr dazu gern beim nächsten Treffen, falls das jetzt nicht ganz verständlich war.Hierin evtl. noch Anregungen zur liste der Natures of Publication: https://www.ideals.illinois.edu/handle/2142/14547
Viele Grüße
Christian
I’m not sure how useful it would be to encode the calendar used. The use of @when already implies the Gregorian calendar. If other calendars were permitted in CMIF, the correspSearch interface would have to be adjusted accordingly, which would make things more complicated for users.
[…] werden können, wie z.B. im Brief erwähnte Personen. Die Weiterentwicklung ist im Artikel “Perspectives of the further development of the Correspondence Metadata Interchange Format” skizziert und kann dort auch diskutiert […]
[…] Perspectives of the further development of the Correspondence Metadata Interchange Format (CMIF), 2015, Stefan Dumont : Lien […]
[…] Supplier Collaboration and Relationship Management: Further developed correspondence, information sharing, and execution checking foster more grounded organizations with providers, […]